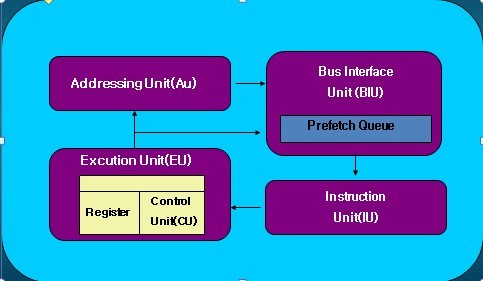
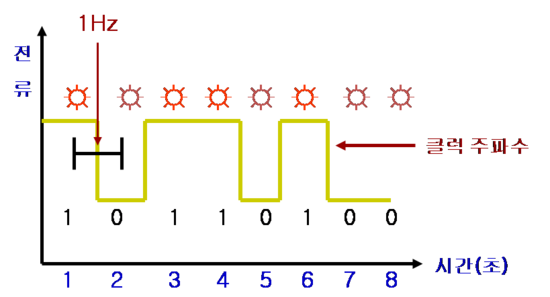
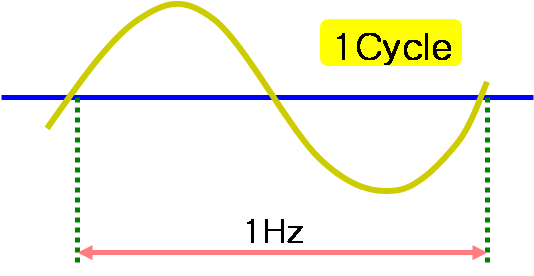
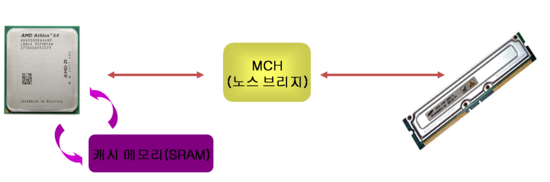
* 인터넷 검색의 결과로 한 포스팅이기 때문에 사전적 의미나 정확한 사실과 차이가 날 수 있음을 양해 구합니다. 공부용 목적으로 포스팅 하였습니다.
* 저작권의 문제 발생시 바로 삭제, 비공개하겠습니다. 지적 부탁드립니다.
목표 : OS의 역사와 발전상, 그리고 여러 종류에 대해 알아본다.
목차 : 1. OS란?
2. OS의 시대별 변천사
3. 종류별 OS의 발전상
1. OS란?
Operating System 의 약자이다. 우리나라로 넘어올 때 '운영체제'라는 단어로 번역되어 지금까지 사용중이다. 뜻을 풀이하자면 컴퓨터의 하드웨어와 소프트웨어를 제어하여, 사용자가 컴퓨터를 쓸 수 있게 만들어주는 프로그램을 말한다.
컴퓨터 안의 디바이스(장치)들이, 예를 들어 프린터가 홀로 알아서 인쇄를 한다던가, 모니터가 홀로 알아서 화면을 출력할 수는 없다. 장치들이 각각의 기능을 하려면 그것을 관리하고 명령하고 제어하는 시스템이 있어야 하는데 이것이 운영체제, 즉 OS인 것이다.
OS는 1950년대부터 지금까지 꾸준히 발전하여 왔고, 현재는 가장 많이 쓰이는 윈도우즈 부터 맥 OS, 그리고 유닉스와 리눅스등이 발전하고 있다.
2. OS의 시대별 변천사
1) 일괄처리 시스템(1950년대)
초기 운영체제의 형태로 일괄 처리 시스템(batch processing system)이 있다. 여러개의 작업을 단일 작업으로 묶어서 일괄 처리하는 시스템으로 전송 속도가 빠른 자기 테이프나 자기 디스크와 같은 보조기억장치를 이용해서 프로세서를 구동시켰으나 보조 기억장치의 속도가 느려 자료를 처리하는 시간이 많이 걸렸다. 이를 보완하기 위해 모니터링 (monitoring), 버퍼링(buffering), 스풀링(spooling) 등 여러 가지 방법을 생각하게 되었는데, 이것들은 아직도 운영체제에서 중요한 개념들이다.
'모니터링'은 CPUT의 유휴시간(idle time)을 효율적으로 사용하기 위해 CPU의 프로세스를 지속적으로 관찰하여 작업 순서를 자동으로 바꾼다. '버퍼링'은 CPU가 어떤 작업을 처리하는 동안, 버퍼에 다음에 처리할 작업을 미리 읽어 자장해 두는 것이다. '스풀링'은 속도가 빠른 디스크를 버퍼처럼 사용해서 미리 입출력 장치에서 익는 것이다.
이러한 일괄처리 방식은 현대의 일반 시스템에서는 거의 사용하지 않는다. 아직까지 일괄 처리 방식을 사용하는 시스템이라면 펜 등으로 마킹한 카드를 읽어 점수를 처리하는 성적 처리 시스템 정도일 것이다.
2) 다중 프로그래밍 시스템(1960년대)
일괄 처리 방식이 CPU를 비효율적으로 사용하는 것을 착안해 이를 개선하여 발전시킨 것이 다중 프로그래밍 시스템(multi-programming system)이다. 이 방식은 CPU유휴시간에 다른 프로세스를 처리하여, 입출력 장치와의 속도차이를 해소한다.
따라서 실제 CPU 에서는 한 개의 프로그램만 실행되며, 나머지 프로그램은 입출력을 수행하거나 대기 상태가 된다. 단점은 메모리에 여러 프로세스를 수용해야 하므로 메모리 관리가 복잡해지며, 실행 대기중인 프로세스간에 처리 순서를 스케줄링 해야 한다는 것이다.
3) 실시간 처리 시스템(1960년대)
일괄처리 시스템과 다중 프로그래밍 시스템 모두 사용자가 지금의 시스템처럼 명령을 내리고 이를 바로 실행할 수 있는 형태가 아니었다. 운영체제에 특정한 작업을 동작시키면 끝날때 까지 아무것도 못하는 시스템이었다.
실시간 처리 시스템(real-time processing system)은 일정시간 동안 정해진 프로세스를 실행한 후 다음 프로세스에 대한 대기와 실행 등을 제어할 수 있다. 이 시스템은 공정 제어 기계나 의료기 시스템 등에 사용되고 있다.
4) 시분할 처리 시스템(1960년대)
우리가 현재 가장 일반적으로 사용하고 있는 운영체제와 비슷해진 것은 시분할 처리 시스템(time-sharing system)부터다. 시분할 처리 시스템은 프로세스의 사용시간을 작게 나누어 다중 사용자(multi-user)나 여러 작업을 한대의 컴퓨터에서 할 수 있게 되었다.
5) 분산 처리 시스템(1980년대)
분산 처리 시스템(distributed data processing system)은 하나의 대형 컴퓨터에서 수행하던 기능을 분산된 여러 컴퓨터에 분담시킨 후, 네트워크를 통하여 처리하는 방식이다. 이에 대한 표준으로는 코바(CORBA, Common Object Request Broker Architecture)가 있다. 코바는 네트워크에서 분산 프로그램 객체를 생성, 배포, 관리하기 위한 구조와 규격이며, 네트워크에서 이기종간의 시스템이 서로 통신할 수 있도록 하였다.
6) 다중 처리 시스템(1990년대)
다중 처리 시스템(multi-processing system)은 여러 개의 작업을 하나의 시스템에서 동시에 처리할 수 있는 시스템을 말한다. 그 대표적인 경우로는 리눅스 시스템이 있는데, 각각의 CPU가 언제나 실행중인 프로세스를 갖도록 하여 CPU의 활용을 극대화하는 것이다. 프로세스의 수가 CPU보다 많은 경우(대부분의 경우가 이렇다), 나머지 프로세스들은 실행되기 위해서 CPU를 사용할 수 있을때까지 기다려야 한다.
다중 처리는 간단히 설명하면, 프로세스가 무언가를 기다려야 하기 전까지는(보통은 시스템 자원을 기다린다) 계속 실행되며, 기다리고 있다가 자원을 얻으면 프로세스는 다시 실행되는 것이다. DOS와 같은 단일 처리(uni-processing)시스템에서 cpu는 아무 것도 하지 않고 대기시간을 낭비한다.
반면에 다중 처리 시스템에는 동시에 많은 프로세스가 메모리내에 존재하며, 프로세스가 무언가를 기다려야 할 때마다 운영체제는 다른 대기중인 프로세스가 CPU를 사용하도록 한다. 어떤 프로세스가 다움에 실행되는 것이 가장 적당한 것인지를 선택하는 일은 스케줄러의 역할이다. 리눅스는 공정한 여러가지의 스케줄링 정책을 사용한다.
운영체제에 대한 다른 관점으로는 윈도우, 리눅스, 유닉스, 넷웨어(Netware), 매킨토시(Macintosh)와 같이 그 종류를 생각할 수 있다. 좀 더 세분화하면 매우 다양하지만 윈도우가 운영체제의 80% 이상을 차지하고 잇는 것이 현실이며, 서버 역시 윈도우 제품군의 사용률이 많이 증가하고 있다.
하지만 대형 서버의 경우에는 IBM의 AIX, HP의 HP-UX, SUN의 Solaris가 아직도 강세다. 아직까지 윈도우가 대형 서버로 동작하고 있는 경우를 본 적이 없지만 앞으로는 어떻게 될지 예측할 수 없다. 하지만 역시나 서버 시장에서 윈도우 시스템은 그다지 환영받고 있지 못하다. 서버 관리자 중 윈도우 서버를 좋아하는 관리자 역시 아직 본 적이 없다.
3. 종류별 OS의 발전상
★유닉스
1) 유닉스의 탄생
UNIX가 탄생하게 된 시기는 1960년대 후반이었다. UNIX OS(Operating System)를 말 할 때는 두 사람을 빼놓을 수 없는데, 그 중 한 사람은 켄 톰슨(Ken Tompson)이고, 나머지 한 사람은 데니스 리치 (Dennis Richie)라는 인물을 꼽을 수 있다. 그 중에서 켄 톰슨은 "UNIX의 아버지"라고 불리고 있으며, UNIX OS를 직접 만든 장본인이기도 하다.
1965년에 MIT공대와 GE(General Electric)사에서 합작하여 다중 사용자 환경을 구현하기 위한 일환으로 AT&T사의 BELL LAB연구소에서 MULTICS(MULTIplexed Information Computing System ) OS개발 PROJECT를 추진하게 되었는데, 켄 톰슨은 그 PROJECT의 한 일원으로 시스템 프로그래머로 일하게 되었고, 결국 MULTICS OS가 완성되어 GE사 제품의 "GE 645" 컴퓨터에 탑재하였으나, 수행 SPEED가 너무 느리고 사용이 복잡하여, 불행하게도 MULTICS PROJECT는 1969년에 중단 되었다.
그러나 톰슨은 MULTICS OS와 CMAS(Cambrige Multiple Access System), CTSS(Compatible Time Sharing System)의 장점을 수용하여, 새로운 OS 즉 "PROJECT에 참여하는 여러 프로그래머 간에 개인의 DATA는 보호하면서, 공유해야 할 DATA는 여러 사람이 쉽게 사용할 수 있도록 해주는 OS"를 개발하였는데, 그것이 바로 최초 "UNIX OS"로 1969년에 PDP-7 미니 컴퓨터 장비에서 움직이는 OS가 된 것이다.
당시 OS명칭은 다목적용인 MULTICS OS에 대응시켜 단일목적의 의미를 갖는 UNICS(UNIplexed Computing System) OS로 불리였으나, 후에 UNIX로 정식 명칭을 바꾸었고, 최초 UNIX OS는 상업적인 목적에서 개발된 것이 아니고, 숙련된 프로그래머를 위해 PROJECT 개발시 보다 편한 개발환경 제공차원에서 만들어진 것이 다른 OS와 주된 차이점이라 할 수 있다.
그러나, 최초에 만들어진 UNIX OS는 단일 사용자를 지원하는 OS였으며, OS 소스 코딩도 PDP-7 컴퓨터의 ASSEMBLY 언어로 작성되어, 기계 종속적인 OS로 주로 AT&T사의 BELL LAB연구소에서만 사용 되었다. 켄 톰슨은 시스템 프로그래머로 프로그램 언어에도 상당한 관심을 가지게 되었는데, 당시 ALGOL언어를 수정하여 Cambrige 대학에서 만든 BCPL( Basic Combined Procedure Language) 언어의 구조적 프로그래밍 개념을 도입하여 B 언어를 1971년에 완성하게 되었고, 이때 데니스 리치는 켄 톰슨의 B언어를 대폭 수정하여, 영문 알파벳 "B" 다음의 "C"를 의미하는 C 언어를 1972년에 고안하게 된다.
당시 C 언어는 다른 고급수준 언어와 대별되는 차이점이 있었는데, 그것은 구조적 프로그래밍 기법을 갖는 고급언어(High Level Language)의 성격과 저급 수준언어(Low Level Language)가 갖는 BIT단위 처리가 가능한 점으로 OS의 소스 코딩을 C 언어로도 가능하게 된 점인데, 이러한 C 언어의 개발이 없었더라면 오늘날의 업계의 표준인 UNIX OS로 자리를 굳히지 못하였을 것이다.
켄 톰슨과 데니스 리치는 1973년 PDP-11 장비에서 탑재된 UNIX OS를 C 언어로 코딩하는데 성공하였으며, 이때부터 UNIX OS는 이식성이 강한, 다중 사용자를 지원하는, 간결하면서 프로그램 개발이 용이한 언어로 탄생하게 된다.
최초 C 언어로 작성된 소스코드는 약 11000 라인으로 그 중 95%인 10000 라인은 C 언어로 작성되었고, 나머지 1000 은 ASSEMBLY 언어로 작성 되었는데, 그 중에 800 라인은 기계 종속적인 부분 때문이고, 나머지 200 라인은 수행 SPEED를 높이기 위한 목적으로 작성되었으며, 이후 다른 장비에 이식(PORTING)은 약 5% 의 소스만 수정하면 간단하게 되었다.
2) UNIX OS의 탄생 이후 ......?
어떻게 UNIX OS가 세상에 알려지게 되는가? 또 UNIX OS가 갑자기 급 부상하게 된 것은 무엇 때문인가? 70년대와 80년대까지의 역사를 위주로 살펴 보겠다.
처음 UNIX OS가 탄생하게 된 배경은 단지 프로그래머의 개발 환경을 개선해 주겠다는 순수한 취지만은 아니었고, 그 이면에는 켄 톰슨의 개인적인 문제와 AT&T의 회사정책도 포함되어 있다.
MULTICS OS개발이 무산되고 난 후 켄 톰슨은 태양계 행성의 움직임을 알아보는 우주여행(SPACE TRAVEL) 모의실험( SIMULATION)을 연구 중이였는데, 당시 PDP-11장비에 MULTICS OS를 이용하기에는 비용이 너무 비싸다는 문제와, 또 MULTICS OS의 실패 등으로 연구 개발 비용 지원이 용이하지 않아 경영진이 만족 할만한 또 다른 제품개발을 해야 하는 등 여러 가지 문제에 봉착하게 되었고, 결과적으로 값싼 PDP-7장비에 문서처리 기능을 갖춘 UNIX OS를 개발하게 되었다.
여하튼 1971년 UNIX OS는 AT&T사의 정식제품으로 등록 되었고, AT&T사 내에서 원하는 사람은 무료로 사용할 수 있도록 허가 되었다. 1974년 7월에는 최초로 일반인에게 UNIX OS가 소개되었는데, 이는 켄 톰슨과 데니스 리치가 CACM 학술지에 " The UNIX Time-Sharing System "이라는 논문을 내놓으면서부터 이다.
1976년에는 UNIX OS가 오늘날 세계적으로 알려지게 되는 중요한 계기를 맞는 해가 되었는데, 그것은 AT&T사에서 UNIX OS를 일반 대학교나 연구소에 거의 무료로 UNIX OS 전체 소스코드를 보급하기로 결정하면서부터 시작 되었다..
그 당시만 해도 UNIX OS를 제외한 운영체제(OS)는 해독하기 어려운 ASSEBLY 언어로 구성되어 있었고, 그나마 KNOW-HOW로 알려져 그 중 일부만 공개되어 있는 실정이기 때문에, 일반 대학이나 연구기관에서 특정 OS의 내용을 분석한다는 것은 거의 불가능한 것으로 여겨 졌으나, AT&T사에서 OS 소스코드를 비영리기관이나 교육기관에 공개하므로 일대 변혁을 가져오게 되었다.
AT&T사의 이와 같은 결정은 두 가지 이유가 있었는데 하나는, 당시 AT&T사는 전신 전화를 담당하는 대표기관으로서, OS나 컴퓨터 판매로 이윤을 얻는 사업은 할 수 없도록 법적으로 제제가 되어 있었고, 두 번째 이유로는 어떻게든 UNIX OS를 개선 발전시켜야 한다는 목적에서 취해진 결정이다.
UNIX OS를 헐값에 공급 받아 가장 큰 발전을 기하게 된 대학으로는, 캘리포니아 대학의 버클리 분교인데, 1970년대
말에서 1980년대 초까지 기존 OS를 전면적으로 연구하여 많은 기능을 추가 시켰고, 나름대로 "BSD(BERKELEY SOFTWARE DISTRIBUTION)"라는 명칭으로 VERSION을 체계적으로 관리하게 된다. BSD3, BSD4, BSD4.3 VERSION으로 계속 발전을 거듭하면서 C SHELL, VI EDITOR, LISP, PASCAL, SOKET COMMUNICATION, VIRTUAL MEMORY등 아주 유용한 기능들이 새로 추가 되었다.
한편 AT&T에서도 UNIX OS에 대한 계속적인 연구가 진행되었는데, AT&T에서는 1976년에 UNIX V6을 무료로 공급한 후 UNIX V7으로 VERSION UP을 하고 "SYSTEM" 이라는 명칭을 부여하여 체계적으로 VERSION을 관리하게 되었는데, SYSTEM III, SYSTEM V 가 대표적인 AT&T의 UNIX OS로 자리잡게 된다.
1980년대 초까지 UNIX OS는 기업체나, 연구소, 대학에서 사용하기 편하게 기능을 부여한 수정판이 몇 백 본이 될 정도로 폭 넓게 사용 되어지게 되니 그야말로 춘추 전국시대가 된다.
3) 통합화를 통한 UNIX OS의 성숙기......?
1980년 초, UNIX OS를 제공했던 AT&T사에서는, 드디어 UNIX OS를 상업적 이윤을 목적으로 판매할 계획을 하게 되지만, 가장 큰 문제는 여기 저기에서 사용되고 있는 많은 UNIX OS의 여러 기능들을 잘 통합하여 일원화된 UNIX OS를 보급하는 것이였다.
상업적 판매를 위한 일환으로 1982년에 AT&T사에서는 그 당시 주류를 이루어 왔던 SYSTEM계열과 BSD계열의 특징적인 기능을 통합하여, SYSTEM III를 발표하게 되고, 1983년에 BSD의 최종판인 4.3 VERSION의 기능까지 통합하여 SYSTEM V를 내놓으면서 본격적인 판매를 시작하게 된다.
물론 AT&T사에서 이러한 결정을 하기에는 자사의 많은 권한을 포기 해야 했고, 그래도 당시 UNIX의 인기는 급상승하여, 세계에 널리 알려져 있었으므로, 그 수익성도 많을 것으로 기대되어 이러한 결정을 강행하게 된다.
AT&T사는 점점 UNIX OS에 대한 성장잠재력을 알게 되었고, 당시 UNIX WORKSTATION 부문에서 가장 잘 알려진, SUN 마이크로 시스템즈사와 함께 "UI(UNIX INTERNATIONAL)"라는 기구를 창설하여, 세계 UNIX시장의 석권을 꿈꾸게 된다. 그때 SUN의 WORKSTATION에는 SunOS라는 UNIX OS가 탑재 되었는데, 그것은 버클리 대학의 BSD 4.3 VERSION을 기반으로 한 UNIX OS 였다.
이러한 UI기구 결성은, UNIX의 2대 조류가 연합하였다는 사실 하나만으로도 다른 컴퓨터 업계에서는 큰 충격으로 받아들여 지게 되었다. 이러한 컴퓨터 업계로는 UNIX 사업에 비교적 빨리 뛰어 들었던 휴렛팩커드(HP), 대형 컴퓨터에서 타의 추종을 불허하는 IBM, DEC사로, 각 사는 SYSTEM계열과 BSD계열의 OS특징에 자체적으로 여러 가지 KNOWHOW를 가미한 약간 독자적인 OS를 제공하고 있었다.
HP는 "HP-UX",IBM은 "AIX", DEC은 "Ultrix"라는 OS가 바로 그것이다.
위협을 느끼게 된 HP, IBM, DEC사도 UI기구에 맞설 수 있는 기구를 창설하게 되었는데,그것은 바로 "OSF(OPEN SYSTEM FOUNDATION)"이다. 눈뜨고 당할 수는 없다는 차원이었다. 일반 UNIX를 사용하는 업체에서는 이러한 현상에 우려의 목소리가 높았고, 그것은 어렵게 UNIX OS가 통합되는가 했더니, 또다시 서로 다른 형태로 분리 발전되어 나가는 점을 우려한 것이었다. 결국 UI와 OSF는 서로 경쟁하면서 서로 다른 신제품을 계속 개발하게 된다.
예를 들면 UNIX에서 제공하는 GUI(Graphical user interface)로 UI에서는 OPEN LOOK을 지원하게 되고, OSF에서는 Motif를 지원하게 되어, UNIX에서 제공하는 X-WINDOW가 어느쪽의 기술구조를 따르는가에 따라 내부적으로 서로 상이한 구조를 가지게 된다.
당시 UNIX OS는 PC업계에서도 많은 관심을 가지게 되었으며, 마이크로 소프트웨어사의 Zenix와, 또 다른 제품인 LINUX가 PC용 UNIX OS로 발표되었고 이외에도 약 10여종의 PC용 UNIX가 발표되어 PC이용자에게 각광을 받게 된다.
또한 UNIX시스템의 여러 분야에 "표준화 기구"가 참여하여 표준을 정하게 되는데, 이것은 UNIX시스템에서 사용되는 모든 S/W를 일정한 규칙이나 틀에 맞추어 개발하게 함으로, 비록 UNIX DB, UNIX OS, UNIX SYSTEM이 서로 다르더라도 상호간에 원활히 운영할 수 있는 호환성을 목적으로 추진되어 오늘날 "OPEN시스템"이 등장하게 되는 계기를 마련되게 된다.
이러한 표준화 기구로는 ANSI, IEEE, ISO, POSIX, XOPEN, FIPS등을 들 수 있는데, 그 중에 최근 XOPEN 기관에 의한 1170 SPEC의 표준은 UNIX OS설계에 대한 표준으로, 이 표준에 맞추어 OS를 개발하게 되면, 향후 기종에 무관하게 적합한 OS를 사용자가 선택하여 사용할 수 있는 등 사용자의 기존 투자비용을 보호 받을 수 있는 이점도 제공 받을 수 있게 된다.
최근에는 UI나 OSF도 각자의 독자노선에서 벗어나 UNIX를 통합하여 통일성 있게 개발하자는데 뜻을 같이하여 결국 AT&T사의 SYSTEM V 계열의 OS인 SVR4를 UNIX 표준OS로 정하였고, UNIX업체에서도 그에 맞추어 OS를 재 설계하게 되는데, SUN사의 SunOS도 SYSTEM V OS구조로 바꾸면서 그 명칭을 "SOLARIS"라고 바꾸게 되며, HP사의 HP-UX도 VERSION 10부터 SYSTEM V OS를 완벽하게 수용하게 된다.
UNIX OS의 취약한 기능들 즉 OLTP 처리기능, 시스템 보안기능, 분산 처리기능, 시스템통합 관리 기능 등이 계속 보완 되었으며, 주변기술 즉 전세계를 하나의 망으로 연결하는 INTERNET 기술, 대용량의 데이터를 처리할 수 있는 데이터베이스 기술, 지역적으로 떨어져 있는 컴퓨터간에 연계 처리하는 분산처리 기술, 일반 사용자를 위한 GUI기술들이 상당히 급진전하고 있다. 물론 컴퓨터 하드웨어 기술도, 최근 해를 거듭할수록 발전하여 하나의 CPU로 TIME SHARING하여 다중 처리하던 방식에서, MEMORY를 수 십 개의 CPU가 공유하면서 병렬 처리하는 SMP(SYMMETRIC MULTI-PROCESSOR) UNIX 장비도 개발되었으며, MEMORY를 공유하지않고 UNIX 컴퓨터를 여러 대로 묶어, 고속의 통신라인을 통해 병렬 처리하는 MPP(MASIVELY PARALLEL PROCESSORS) UNIX장비가 발표되어, 이제는 기존 HOST컴퓨터와 거의 동일한 성능의 UNIX장비가 계속 발표되고 있고, 실 사용업체도 많아지고 있다.
★리눅스 (Linux)
리눅스는 1991년 당시 헬싱키 대학 2학년생이던 리누스 토발즈가 자신이 수강하던 유닉스 과정의 교재였던 한정판 유닉스인 미닉스를 보고 단지 재미로 자신의 PC에서도 써보고자 하는 의도에서 만든 운영체제이다.
리눅스의 첫 공식 버젼은 1991년 10월 에 발표되었으며 1992년 1월에는 100명의 이용자가생겼다.
리눅스가 뉴스 그룹을 타고 공개되면서 많은 사람들이 이 공개용 리눅스에 대해 관심을 가지게 되었다. 더욱이 이 소스는 AT&T의 유닉스 관련 저작권에도 저촉되지 않는 것이었다.
그 후 스톨만 교수가 주축이 된 GNU그룹에서 이 리눅스 소스 코드를 가지고 프로젝트를 진행하게 되었고 이일을 계기로 전세계 의 수많은 개발자들이 리눅스의 소스코드를 받아 자신이 원하는 기능을 추가하고 다시 인터넷에 공개하는 방식으로 발전해갔다.
이와 같은 전세계적인 개발 방식이 리눅스의 급속한 성장의 계기가 되었다.
현재 IBM과 같은 대기업에서도 리눅스에 대해 상당한 관심과 투자를 아끼지 않고있고 윈도우즈와 인텔사에 대해 반대하는 회사들의 투자와 지원으로 많은 관심을 끌고 있다.
<리눅스의 특징>
1. 리눅스는 무료판이며 완전한 공개 운영체제이다. (소스가 공개되있다,)
2. 유닉스와 유사한 형태를 가지고 있다. 리눅스는 유닉스의 한 계열이라고 불러도 될 정도로 유사한 모습을 가지고 있다.
3. 서버용 소프트웨어를 기본적으로 제공한다.
4. 무료로 다운받아 설치할 수 있으며 수많은 배포판이 있다.
<리눅스의 단점>
리눅스의 단점은 유닉스가 가지고 있는 단점들과 유사한 점 이 많다.
1. 책임지고 개발하는 사람들이 적다.
2. 현재도 개발되고 있는 운영체제이다.
3. 리눅스는 컴퓨터에 대한 많은 지식을 요구한다.
리눅스는 전세계 개발자들이 자발적으로 참여하고 만들어가는 운영체제이기 때문에 사용자가 곧 개발자인 경우가 많다. 또한 문제가 생겼을때 알아서 해결해야 한다.
★ OS/2
IBM사가 개인용 컴퓨터를 위해 만든 GUI 운영체제 입니다. 맨 처음에는 마이크로소프트사와 함께 개발하다가 결국에는 결별을 선언하고 단독으로 개발하게 되고, 이후 윈도와 치열하게 경쟁하는듯 하다가 윈도 95의 등장과 함께 서서히 역사의 뒤안길로 사라져버린 불운의 운영체제 이다.
윈도보다 뒤지는 부분도 없었고, 오히려 상당히 많은 부분에서 안정성과 성능이 뛰어났지만
"훌륭하게 잘 만들어진 제품은 알아서 잘 팔릴것"이라는 생각으로 마이크로소프트에 비해 상대적으로 마케팅을 소홀히 하는 바람에 치명적 타격을 입게 된다.
뿐만 아니라, Windows 3.0때부터 윈도는 수 많은 컴퓨터와 함께 번들되어 제공되었지만 OS/2는 독립된 비싼 패키지로 판매되었으며, 윈도가 많은수의 하드웨어를 지원하는데 반해 OS/2는 IBM계열을 제외하곤 하드웨어 지원이 상대적으로 많이 부족했기 때문에 윈도와의 경쟁에서 밀려버렸다.
OS/2는 원래 마이크로소프트사와 IBM사가 함께 노력해서 개발되었고 1987년에 첫번째 버전이 출시되었다.
IBM과 마이크로소프트 둘 다 각자의 상표를 붙여서 자신들만의 버전을 발표한다.
OS/2 1.x 버전은 80286에서 실행되도록 설계된 16비트 운영체제 였다.
OS/2 1.3 버전은 1991년에 출시되었는데 이 시기가 바로 마이크로소프트사와 IBM사가 결별을 선언하고 운영체제에서 자신들만의 길을 걷기 시작한 시기이다. IBM은 IBM OS/2 2 버전의 개발에 착수했고, 마이크로소프트사는 기술의 일부를 가져와서 Windows NT를 만드는데 사용하게 된다.
★ 맥 OS
매킨토시 컴퓨터의 운영 체계(OS). 매킨토시 OS라고도 한다. 맥 OS는 당초 매킨토시 시스템 소프트웨어의 일반적인 호칭이었으나 현재는 매킨토시용 OS의 이름으로 정식 채용, 상표가 되었다. 1984년에 처음으로 매킨토시를 발매한 이래 매킨토시의 OS는 마우스 조작에 의한 그래픽 사용자 인터페이스(GUI)나 윈도 표시를 재빨리 채용한 것으로 주목을 끌었다. 앞으로 랩소디(Rhapsody)라는 코드명으로 새로운 OS가 등장할 예정인데, 이것은 맥 OS의 조작 감각(look and file)을 가진 내부 구조를 대폭 변경해서 성능 향상을 도모한 것이다. 또 개인용 컴퓨터(PC) 호환기나 윈도즈상에서도 랩소디를 동작시킬 예정이다.
4. 1998년 이전까지의 OS 변천사 정리 (출처 네이버 블로그 http://blog.naver.com/dbman/40006608589)
1981년 10월
새로운 IBM PC를 위한 PC-DOS 1.0 이 발표되다. 곧 Microsoft는 MS-DOS를 발표했고,모든 희망자에게 라이선스를 부여한다.
1983년 1월
애플 컴퓨터는 최초의 그래픽 기반 인터페이스를 가진 마이크로컴퓨터의 하나인 Lisa를 개발했다. 신뢰성이 약한 하드웨어와 약 1만 달러에 달하는 가격으로 Lisa는 실패하게 된다. 그러나, 일년 후 적당한 가격의 Macintosh를 내놓는 계기를 마련하게 된다. Lisa와 Mac은 DOS 신봉자들을 비웃기라도 하듯 WIMP(Windows, Icons, Mice, Pointers) 인터페이스를 제공한다. 또한 폴더와 긴 파일 이름도 이 때 나오게 된다. 이것은 Windows 2.0에서야 겨우 지원하기 시작한 것이었다. 또한 몇몇 기능은 윈도95가 나와서야 겨우 구현되었다.
1983년 3월
사실상 다시 제작된 MS-DOS 2.0은 하드 디스크, 큰 프로그램들과 설치 가능한 디바이스 드라이버, Unix를 모방한 계층적 파일 시스템을 지원하게 된다. 여전히 파일 이름은 8자를 넘을수 없었고, 텍스트 모드의 인터페이스를 갖고 있었다.
1983년 10월
DOS 스프레드시트인 VisiCalc의 개발사에서 떨어져 나온 VisiCrop.는 최초의 PC를 위한 GUI인 "환경 통합적인" VisiOn을 발표했다. VisiOn은 512KB의 램과 하드 디스크를 필요로 했다. 이때까지만 해도 이것은 최첨단 기술이었다.
1983년 11월 10일
Microsoft는 DOS를 그래픽 인터페이스를 통해 기능을 확장하는 윈도우 환경을 발표했다.
1984년 9월
Digital Research에 의해GEM (Graphics Environment Manager)가 발표되었다. GEM은 DOS 어플리케이션을 실행할 수는 없었고 이로 인해 경쟁력이 없었다. GEM과 VisiOn은 윈도 시장을 공격했지만, 오리지날 윈도우가 그랬듯이 똑같은 문제에 부딪치게 되었다. 이 새로운 플랫폼들에서 사용할 수 있는 어플리케이션이 거의 없었던 것이다.
1985년 2월
IBM은 텍스트를 기반으로 한 DOS에서 다중 작업을 할 수 있는 TopView를 발표했다. TopView에서는 몇몇 도스 명령만 사용할 수 있었다. TopView는 거의 모든 DOS 인터럽트를 가로채었기 때문에 DOS의 배치 파일이 실행될 수 없었다. IBM은 TopView에 GUI 환경을 덧붙이겠다고 약속했지만 결국엔 그것은 실현되지 않았다.
1985년 7월
Quarterdeck Office Systems이 또 다른 DOS를 위한 다중 작업 도구인 DESQview를 발표했다. 이것은 한동안 일부 사용자들 사이에서 성공을 거두었다. Quarterdeck은 DESQview를 플랫폼으로 만들기 위해 개발자들을 독려했다. 그러나 Windows 3.0이 표준이 되면서 결국 두 손을 두는 수 밖에 없었다.
1985년 11월 20일
Windows 1.0이 발표되었다. 1.0 버전은 사용자들이 한번에 여러개의 프로그램을 사용할 수 있도록 했다. 개별 어플리케이션을 종료하거나 다시 실행할 필요없이 쉽게 어플리케이션을 전환할 수 있었다. 그러나, 윈도우 위에 윈도우를 겹쳐서 배열할 수 없어서 큰 불편함이 있었다. Windows 1.0을 위한 소프트웨어가 충분하지 않았고 시장을 공략하는데는 실패했다.
1987년 1월
Windows 1.0에서 작동하는 Aldus PageMaker 1.0이 발표되었다. PageMaker는 최초의 PC에서 WYSIWYG 방식을 지원하는 출판 도구였다. 데스크탑 출판 어플리케이션의 인기와 레이저 프린터의 발매는 Windows가 데스크탑을 석권하는데 큰 힘이 되었다.
*WYSIWYG 란?
What You See Is What You Get (당신이 보는 것이 당신이 얻는 것)의 약어. 화면에 보이는 것과 동일한 인쇄 출력을 얻을 수 있는 기술을 가리키는 말로 매킨토시가 제공하는 탁상출판기능(DTP: Desk Top Publishing)이 대표적이다.
1987년 4월
IBM과 Microsoft는 운영 체제에 대한 원대한 꿈인 OS/2 1.0을 발표했다. Microsoft는 Windows의 개발을 계속했고 차세대 PC의 운영 체제에 대한 방책을 생각하고 있었다. OS/2 1.0은 GUI를 갖추지 않았다. 그리고 결국엔 부족한 어플리케이션, 하드웨어 지원 미흡, DOS 어플리케이션에 대한 미약한 지원, 이것을 사용하기 위해 PS/2를 사야하는지에 대한 혼동등으로 인해 실패하고 말았다.
1987년 10월 6일
PC에서 GUI 를 지원하는 최초의 스프레드 시트인 Excel for Windwos 2.0이 Lotus 1-2-3의 아성에 도전하며 시장에 나섰다. Excel은 Windows가 정통성을 얻는데 조력했지만, 많은 자원을 요구하고, Windows 디바이스 드라이버에 의존하는 것은 이 새로운 도전자의 약점이 되었다.
1987년 12월 9일
Windows 2.0이 발표되었다. 이것은 이전 버전의 제목창으로 나열되던 윈도우 구성 대신 겹쳐질 수 있는 윈도우 시스템을 사용했다. 또한 80286 시스템이나 그 이상의 보호 모드를 사용할 수 있었고, 프로그램들이 DOS의 640KB 한계를 넘어설 수 있도록 했다. 1988년 6월에 이르러 2.1 버전이 나왔을 때 이것은 Windows 286으로 이름이 바뀌었다.
1987년 12월 9일
Intel의 최신 칩에 최적화된 2.0 버전인 Windows 386이 발표되었다. 이것은 시장성에 취약점이 있었지만 대부분에 있어서 사용자들이 DOS 프로그램들을 386 칩의 "가상 머신"을 통해 다중 작업할 수 있도록 했다. 이것은 Windows 3.0 개발에 상당한 기반을 제공했다.
1988년 6월
Digital Research는 DR-DOS를 발표했는데 언론은 이것의 강력한 유틸리티로 인해 MS-DOS보다 뛰어나다고 평가했다. 그러나 DR-DOS는 더 이상 발전하지 못했다.
왜냐면 Windows와 함께 동작하려면 패치(patch)가 필요했고, DR-DOS는 시장에서 주목할만한 자리를 차지하지 못했다.
1998년 10월 31일
IBM이 프리젠테이션 매니저를 포함한 OS/2 1.1을 발표했다. GUI를 구현한 최초의 OS/2 1.1은 OS/2 1.0에서 크게 업그레이드한 것이었다. 그러나 여전히 대중적인 DOS 어플리케이션에 대한 지원이 미약했고 현존하는 하드웨어에 대해서도 마찬가지였다.
OS/2의 이러한 문제점은 Microsoft가 Windows를 계속 개발하는데 용기를 주었다.
또한 IBM은 OS/2를 계속 개발해 나갔다. 한동안 시간이 지난 후 IBM은 Microsoft가 Windows에 목적이 있다고 비난했으며 2마리 토끼를 잡으려 한다고 했다.
1988년 12월
최초의 Windows용 워드 프로세서인 Samna Ami가 발표되었다. 사용자들은 출력물의 글꼴과 닮은 글꼴로 편집할 수 있었고, 실제로 나타나는 것과 마찬가지로 여백을 볼 수 있었다. WordPerfect는 워드 프로세서 가운데 독보적인 자리를 차지하고 있었으나, Ami 또한 아주 근소한 차이로 시장에서 상당한 영향력을 갖고 있었다.
Microsoft의 Word for Windows는 조만간 나오게 될 것이었다.
1990년 5월 22일
괄목할만한 사용상 편리함이 개선된 Windows 3.0이 발표되었다. 프로그램 관리자와 아이콘으로 작업하는 것은 MS-DOS가 관리하던 구형 Windows 2보다 훨씬 나았다.
파일 관리자도 새롭게 추가되었다. 개발자들은 자극을 받았고, 곧 윈도우 소프트웨어의 붐이 시작되었다. 안정성은 완벽하지 못했지만 Windows 3.0은 광범위한 제 3의 하드웨어와 소프트웨어 지원 그리고 PC 제작사들의 번들로 제공되므로써 즉시 시장을 장악했다.
Microsoft의 Windows 만들기 작업은 끝내 성과를 거두게 되었다.
1990년 11월
또다른 DOS를 위한 GUI인 GEOS 1.0이 소개되었다. 그러나, 결코 Windows의 경쟁자가 되지는 못했다. PC 매거지과 몇몇 다른 출판물들이 GEOS의 기술상 이점을 떠들어 댔지만, GEOS에서 작동하는 소프트웨어는 없었다. 개발용 소프트웨어조차 OS가 발표된 후 6개월이 지나도록 나오질 않았다.
1992년 3월
OS/2 2.0이 판매를 시작했다. 이 버전은 DOS/Windows 3.x를 잘 지원했다. 그러나, 복잡한 Object- Oriented Workplace 셀과 당시로는 과한 자원이 필요한 것이 부담이었다. OS/2는 여전히 광범위한 드라이버와 제 3의 소프트웨어 지원이 미약했고, Windows가 시장의 선두 주자로 나서고 있었다.
1992년 4월 6일
Windows 3.1이 발표되었다. 여러가지 버그가 수정되었고 보다 안정적이며 몇몇 교체 가능한 트루 타입 폰트들을 포함한 새로운 기능들이 첨부되었다. Windows 3.x는 미국에서 PC들 가운데 가장 많이 인스톨되는 운영체제가 되었고 이것은 1997년까지 계속 되었다.
1992년 7월 4일
Microsoft는 32비트 Windows NT를위한 차세대 API인 Win32를 발표했다. 최초로 "시카고"(윈도95의 코드 네임)에 대한 공개적 언급이 있었다. 또한 NT 제품이 어떻게 현존하는 Windows 아키텍쳐를 대신할 것인지도 얘기 되었다.
1992년 10월 27일
Windows for Workgroups 3.1이 발표되었다. E-메일, 그룹 미팅 스케쥴링, 파일/프린트 공유, 일정 관리, 네트워크와 작업 그룹을 연결시키는 기능을 가지고있었다. 3.1이 소규모 LAN의 붐을 일으킬 조짐을 보였지만 이것은 상업적으로는 실패했다. 덕분에 "Windows for Warehouses (정신병자 수용소를 위한 Windows)"라는 불명예스런 이름을 얻게 되었다.
1993년 4월
6.0 버전에 이르러서 IBM은 PC-DOS를 Microsoft와는 별개로 판매하기 시작했다.
PC-DOS 6.0은 1981년 오리지날 IBM PC에서 Microsoft가 라이선스를 갖고 있던 것과는 다른 종류의 optimizer와 메모리 관리자를 포함하고 있었다. Novell은 DR-DOS를 사서 fancier 네트워킹과 함께 1993년 12월에 Novell DOS 7.0이라는 이름으로 내 놓았다. 이 두 형태의 노력은 너무 미미했고, 또한 너무 늦었다.
왜냐면 DOS가 그 의미 자체에 도전을 받고 있었기 때문이다. 모든 실제적인 PC 신기술은 Windows에서 발생하고 있엇다. Microsoft의 OS가 아니라 말이다.
1993년 5월 24일
Windows NT (New Technology의 약OO만 일부에선 Not Today, No Thanks, Nice Try의 약자라고도 한다)가 발표되었다. 처음부터 파워 유저와 서버 시장을 겨냥한 최초 버전인 3.1은 실행을 위해 최고의 PC를 요구했고 다소 불안정했다. 그러나 Windows NT는 개발자들의 많은 지원을 받게 된다. 왜냐면 보안, 안정성, Win32 API는 보다 쉽게 강력한 프로그램들을 제작하도록 해주었기 때문이다. OS/2 3.0을 위한 프로젝트가 시작되었지만 코드를 몽땅 다시 쓰는 일이 되었다.
1993년 11월 8일
Windows for Workgroups 3.11이 발매되었다. Netware와 WindowsNT에 대한 개선된 기능을 지원하고, 여러 종류의 아키텍쳐와 호환되며 실행속도와 안정성이 개선되었다. 결국 Windows95가 가야할 길을 여기서 찾게 된다. 미국에서는 지금도 이것은 많은 기업에서 사용되고 있다.
1994년 3월
새로운 다중 사용자 유닉스 운영 체제인 Linux 1.0이 취미삼아 시작한 프로젝트로 선을 보였다. 이것은 소스 코드가 공개되어 있어서 누구라도 이것을 자신에 맞게 개조하거나 그 결과물을 전파할 수 있다. 새로운 하드웨어와 소프트웨어는 재빨리 Linux로 포팅되었으며, 자주 Windows보다 더 빠르게 진행되기도 했다. Linux는 큰 시장성을 갖지 못했음에도 계획은 계속 진행되었다( 넷스케이프조차 Windows NT에 대항하기 위해 Linux와 커뮤니케이터와의 결합을 고려한 정도였다). 또한, Linux는 이것에 열광하는 사람들의 큰 도움으로 인해 PC 시스템에서 선택할 수 있는 Unix가 되었다.
1995년 8월 24일
몇번의 지연과 전례에 없는 사전 광고가 끝난 후 Windows 95가 발표되었다. 흥분한 몇몇 사람들은 자신들은 컴퓨터도 없으면서 이것을 사기 위해 대열에 끼어들기도 했다. 최초로 미리 DOS를 설치할 필요가 없는 Windows 95는 여전히 가장 친근한 Windows다. 또한 PC의 주요한 흐름에 박차를 가하는 계기가 되었다. 매우 향상된 인터페이스는 Mac 플랫폼과의 격차를 없었으며 마침내, Mac을 주변부로 밀어내게 된다. 또한 Windows 95는 통합된 TCP/IP 스택, 전화 접속 네트워킹, 긴 파일 이름 지원등이 포함되었다.
1996년 7월 31일
Microsoft는 Windows NT 4.0을 내 놓았다. 3.51에 비해 대단히 진보한 이 버전은 Windows95의 인터페이스와 디바이스 지원이 강화되었고, 몇몇 번들 IIS 웹 서버와 같은 서버 프로세서가 포함되었다. NT 4.0은 기업계에서 Microsoft의 입지를 강력히 굳혀 주었다. Unix를 대신할 지위로써 미국 기업체에서 시작은 작았지만 성장 속도는 그야말로 극적이었다. 또한 인트라넷과 인터넷 사이트를 위한 플랫폼으로 점차 자리를 잡아가고 있다.
1996년 10월October 1996
Windows 95를 위한 OEM Service Release 2 (OSR2)가 새롭게 판매되는 PC에 미리 설치되어 보급되었다. 기능을 향상시키는 Windows95의 제어판 애플릿과 내장된 많은 기능들뿐만 아니라 잠재된 버그를 치료했다. FAT32나 개선된 전화 저속 네트워킹등과 같은 몇몇 "새로운 " 기능들은 윈도98의 기능을 미리 선보인 것이다.
OSR2는 또한 인터넷 익스플로러 3.0을 내장하고 있는데 이것은 Microsoft에서 개발한 최초의 웹 브라우저다.
1997년 9월 23일
Windows NT 5.0의 최초 베타 버전이 개발자들에게 배포되었다. 새로운 버전은 차세대 하드웨어를 지원하게 되며 관리와 보안 기능이 보다 강화되어 있다. 이 버전은 1999년에 발표될 것으로 예상된다.
1998년 6월 25일
Microsoft는 Windows98을 발표했다. 이것은 DOS위에서 움직이는 오래된 커널에 기반한 마지막 Windows 버전이다. Windows 98은 인터넷 익스플로러 4와 결합되어 있으며 USB에서 ACPI 전원 관리와 같은 새로운 디바이스 타입을 지원한다. 차기 Windows의 소비자판은 NT 커널에 기반하여 제작될 것이다.
[출처] OS의 역사|작성자 플래너






 74HC00.pdf
74HC00.pdf 논리 게이트_20100916(이진철).doc
논리 게이트_20100916(이진철).doc